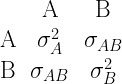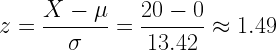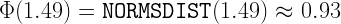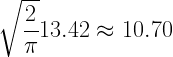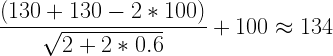
I’m afraid that the question posed by the title does not have a single answer. It depends on how we define and measure academic performance.
Let’s sidestep some difficult questions about what exactly an “academic deficit” is and for the sake of convenience pretend that it is a score at least 1 standard deviation below the mean on a well normed test administered by a competent psychologist with good clinical skills.
Suppose that we start with the 9 core WJ III achievement tests (the answers will not be all that different with the new WJ IV):
| Reading | Writing | Mathematics | |
|---|---|---|---|
| Skills | Letter-Word Identification | Spelling | Calculation |
| Applications | Passage Comprehension | Writing Samples | Applied Problems |
| Fluency | Reading Fluency | Writing Fluency | Math Fluency |
What is the percentage of the population that does not have any score below 85? If we can assume that the scores are multivariate normal, the answer can be found using data simulation or via the cumulative density function of the multivariate normal distribution. I gave examples of both methods in the previous post. If we use the correlation matrix for the 6 to 9 age group of the WJ III NU, about 47% of the population has no academic scores below 85.
Using the same methods we can estimate what percent of the population has no academic scores below various thresholds. Subtracting these numbers from 100%, we can see that fairly large proportions have at least one low score.
| Threshold | % with no scores below the threshold | % with at least one score below the threshold |
|---|---|---|
| 85 | 47% | 53% |
| 80 | 63% | 37% |
| 75 | 77% | 23% |
| 70 | 87% | 13% |
What proportion of people with average cognitive scores have no academic weaknesses?
The numbers in the table above include people with very low cognitive ability. It would be more informative if we could control for a person’s measured cognitive abilities.
Suppose that an individual has index scores of exactly 100 for all 14 subtests that are used to calculate the WJ III GIA Extended. We can calculate the means and the covariance matrix of the achievement tests for all people with this particular cognitive profile. We will make use of the conditional multivariate normal distribution. As explained here (or here), we partition the academic tests 


and
are the mean vectors for the academic and cognitive variables, respectively.
and
are the covariances matrices of academic and cognitive variables, respectively.
is the matrix of covariances between the academic and cognitive variables.
If the cognitive variables have the vector of particular values 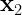

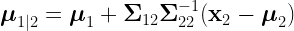
The conditional covariance matrix:
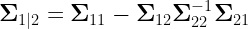
If we can assume multivariate normality, we can use these equations, to estimate the proportion of people with no scores below any threshold on any set of scores conditioned on any set of predictor scores. In this example, about 51% of people with scores of exactly 100 on all 14 cognitive predictors have no scores below 85 on the 9 academic tests. About 96% of people with this cognitive profile have no scores below 70.
Because there is an extremely large number of possible cognitive profiles, I cannot show what would happen with all of them. Instead, I will show what happens with all of the perfectly flat profiles from all 14 cognitive scores equal to 70 to all 14 cognitive scores equal to 130.

Here is what happens with the same procedure when the threshold is 70 for the academic scores:

Here is the R code I used to perform the calculations. You can adapt it to other situations fairly easily (different tests, thresholds, and profiles).
library(mvtnorm)
WJ <- matrix(c(
1,0.49,0.31,0.46,0.57,0.28,0.37,0.77,0.36,0.15,0.24,0.49,0.25,0.39,0.61,0.6,0.53,0.53,0.5,0.41,0.43,0.57,0.28, #Verbal Comprehension
0.49,1,0.27,0.32,0.47,0.26,0.32,0.42,0.25,0.21,0.2,0.41,0.21,0.28,0.38,0.43,0.31,0.36,0.33,0.25,0.29,0.4,0.18, #Visual-Auditory Learning
0.31,0.27,1,0.25,0.33,0.18,0.21,0.28,0.13,0.16,0.1,0.33,0.13,0.17,0.25,0.22,0.18,0.21,0.19,0.13,0.25,0.31,0.11, #Spatial Relations
0.46,0.32,0.25,1,0.36,0.17,0.26,0.44,0.19,0.13,0.26,0.31,0.18,0.36,0.4,0.36,0.32,0.29,0.31,0.27,0.22,0.33,0.2, #Sound Blending
0.57,0.47,0.33,0.36,1,0.29,0.37,0.49,0.28,0.16,0.23,0.57,0.24,0.35,0.4,0.44,0.36,0.38,0.4,0.34,0.39,0.53,0.27, #Concept Formation
0.28,0.26,0.18,0.17,0.29,1,0.35,0.25,0.36,0.17,0.27,0.29,0.53,0.22,0.37,0.32,0.52,0.42,0.32,0.49,0.42,0.37,0.61, #Visual Matching
0.37,0.32,0.21,0.26,0.37,0.35,1,0.3,0.24,0.13,0.22,0.33,0.21,0.35,0.39,0.34,0.38,0.38,0.36,0.33,0.38,0.43,0.36, #Numbers Reversed
0.77,0.42,0.28,0.44,0.49,0.25,0.3,1,0.37,0.15,0.23,0.43,0.23,0.37,0.56,0.55,0.51,0.47,0.47,0.39,0.36,0.51,0.26, #General Information
0.36,0.25,0.13,0.19,0.28,0.36,0.24,0.37,1,0.1,0.22,0.21,0.38,0.26,0.26,0.33,0.4,0.28,0.27,0.39,0.21,0.25,0.32, #Retrieval Fluency
0.15,0.21,0.16,0.13,0.16,0.17,0.13,0.15,0.1,1,0.06,0.16,0.17,0.09,0.11,0.09,0.13,0.1,0.12,0.13,0.07,0.12,0.07, #Picture Recognition
0.24,0.2,0.1,0.26,0.23,0.27,0.22,0.23,0.22,0.06,1,0.22,0.35,0.2,0.16,0.22,0.25,0.21,0.19,0.26,0.17,0.19,0.21, #Auditory Attention
0.49,0.41,0.33,0.31,0.57,0.29,0.33,0.43,0.21,0.16,0.22,1,0.2,0.3,0.33,0.38,0.29,0.31,0.3,0.25,0.42,0.47,0.25, #Analysis-Synthesis
0.25,0.21,0.13,0.18,0.24,0.53,0.21,0.23,0.38,0.17,0.35,0.2,1,0.15,0.19,0.22,0.37,0.21,0.2,0.4,0.23,0.19,0.37, #Decision Speed
0.39,0.28,0.17,0.36,0.35,0.22,0.35,0.37,0.26,0.09,0.2,0.3,0.15,1,0.39,0.36,0.32,0.3,0.3,0.3,0.25,0.33,0.23, #Memory for Words
0.61,0.38,0.25,0.4,0.4,0.37,0.39,0.56,0.26,0.11,0.16,0.33,0.19,0.39,1,0.58,0.59,0.64,0.5,0.48,0.46,0.52,0.42, #Letter-Word Identification
0.6,0.43,0.22,0.36,0.44,0.32,0.34,0.55,0.33,0.09,0.22,0.38,0.22,0.36,0.58,1,0.52,0.52,0.47,0.42,0.43,0.49,0.36, #Passage Comprehension
0.53,0.31,0.18,0.32,0.36,0.52,0.38,0.51,0.4,0.13,0.25,0.29,0.37,0.32,0.59,0.52,1,0.58,0.48,0.65,0.42,0.43,0.59, #Reading Fluency
0.53,0.36,0.21,0.29,0.38,0.42,0.38,0.47,0.28,0.1,0.21,0.31,0.21,0.3,0.64,0.52,0.58,1,0.5,0.49,0.46,0.47,0.49, #Spelling
0.5,0.33,0.19,0.31,0.4,0.32,0.36,0.47,0.27,0.12,0.19,0.3,0.2,0.3,0.5,0.47,0.48,0.5,1,0.44,0.41,0.46,0.36, #Writing Samples
0.41,0.25,0.13,0.27,0.34,0.49,0.33,0.39,0.39,0.13,0.26,0.25,0.4,0.3,0.48,0.42,0.65,0.49,0.44,1,0.38,0.37,0.55, #Writing Fluency
0.43,0.29,0.25,0.22,0.39,0.42,0.38,0.36,0.21,0.07,0.17,0.42,0.23,0.25,0.46,0.43,0.42,0.46,0.41,0.38,1,0.57,0.51, #Calculation
0.57,0.4,0.31,0.33,0.53,0.37,0.43,0.51,0.25,0.12,0.19,0.47,0.19,0.33,0.52,0.49,0.43,0.47,0.46,0.37,0.57,1,0.46, #Applied Problems
0.28,0.18,0.11,0.2,0.27,0.61,0.36,0.26,0.32,0.07,0.21,0.25,0.37,0.23,0.42,0.36,0.59,0.49,0.36,0.55,0.51,0.46,1), nrow= 23, byrow=TRUE) #Math Fluency
WJNames <- c("Verbal Comprehension", "Visual-Auditory Learning", "Spatial Relations", "Sound Blending", "Concept Formation", "Visual Matching", "Numbers Reversed", "General Information", "Retrieval Fluency", "Picture Recognition", "Auditory Attention", "Analysis-Synthesis", "Decision Speed", "Memory for Words", "Letter-Word Identification", "Passage Comprehension", "Reading Fluency", "Spelling", "Writing Samples", "Writing Fluency", "Calculation", "Applied Problems", "Math Fluency")
rownames(WJ) <- colnames(WJ) <- WJNames
#Number of tests
k<-length(WJNames)
#Means and standard deviations of tests
mu<-rep(100,k)
sd<-rep(15,k)
#Covariance matrix
sigma<-diag(sd)%*%WJ%*%diag(sd)
colnames(sigma)<-rownames(sigma)<-WJNames
#Vector identifying predictors (WJ Cog)
p<-seq(1,14)
#Threshold for low scores
Threshold<-85
#Proportion of population who have no scores below the threshold
pmvnorm(lower=rep(Threshold,length(WJNames[-p])),upper=rep(Inf,length(WJNames[-p])),sigma=sigma[-p,-p],mean=mu[-p])[1]
#Predictor test scores for an individual
x<-rep(100,length(p))
names(x)<-WJNames[p]
#Condition means and covariance matrix
condMu<-c(mu[-p] + sigma[-p,p] %*% solve(sigma[p,p]) %*% (x-mu[p]))
condSigma<-sigma[-p,-p] - sigma[-p,p] %*% solve(sigma[p,p]) %*% sigma[p,-p]
#Proportion of people with the same predictor scores as this individual who have no scores below the threshold
pmvnorm(lower=rep(Threshold,length(WJNames[-p])),upper=rep(Inf,length(WJNames[-p])),sigma=condSigma,mean=condMu)[1]



 . What is the average reading comprehension score among students in the gifted education program? If we can assume that reading comprehension is normally distributed
. What is the average reading comprehension score among students in the gifted education program? If we can assume that reading comprehension is normally distributed  and the relationship between IQ and reading comprehension is linear
and the relationship between IQ and reading comprehension is linear  , then we can answer this question using the multivariate truncated normal distribution. Portions of the multivariate normal distribution have been truncated (sliced off). In this case, the blue portion of the bivariate normal distribution of IQ and reading comprehension has been sliced off. The portion remaining (in red), is the distribution we are interested in. Here it is in 3D:
, then we can answer this question using the multivariate truncated normal distribution. Portions of the multivariate normal distribution have been truncated (sliced off). In this case, the blue portion of the bivariate normal distribution of IQ and reading comprehension has been sliced off. The portion remaining (in red), is the distribution we are interested in. Here it is in 3D:

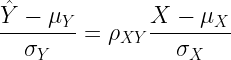


 . If the entire population were given both tests, what proportion would score 70 or lower on both tests? What proportion would score below 70 on the first test but not on the second test? Such questions can be answered with the
. If the entire population were given both tests, what proportion would score 70 or lower on both tests? What proportion would score below 70 on the first test but not on the second test? Such questions can be answered with the 



 is the probability density function of the standard normal distribution (
is the probability density function of the standard normal distribution ( is the cumulative distribution function of the standard normal distribution (
is the cumulative distribution function of the standard normal distribution (